A Service Mesh is an array of network proxies running alongside the services(microservices). It is called “Service Mesh” because the network connections created by proxies running alongside the service creates an illustration of a mesh network. As an architectural pattern, service mesh addresses the networking and application services challenges of microservices architecture.
Why we need Service Mesh?
- The service mesh exists to solve the challenges which are inherited in managing distributed systems. This isn’t a new problem, but it is a problem that many more users now face because of the proliferation(increase greatly) of microservices.
- The service mesh exists to provide solutions to the challenges of ensuring reliability (retries, timeouts, mitigating cascading failures), troubleshooting (observability, monitoring, tracing, diagnostics), performance (throughput, latency, load balancing), security (managing secrets, ensuring encryption), dynamic topology (service discovery, custom routing), and other issues commonly encountered when managing microservices in production.
- The service mesh is different because it’s implemented as an infrastructure that lives outside of your applications. Your applications don’t require any code changes to use a service mesh.
Deep Diving Into Service Mesh
- The exact details of its architecture vary between implementations.
- Every service mesh is implemented as a series (or a “mesh”) of interconnected network proxies designed to better manage service traffic.
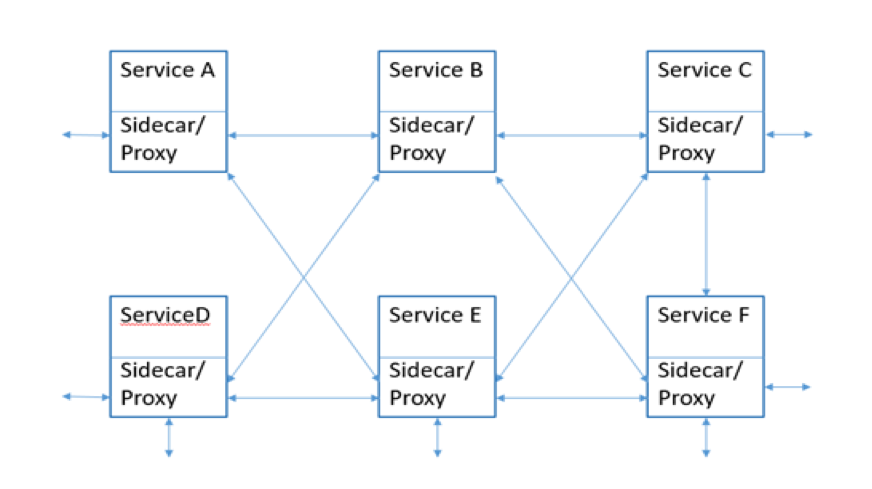
- With a service mesh, each application endpoint (whether a container, a pod, or a host, and however these are set up in your deployments) is configured to route traffic to a local proxy (installed as a sidecar container, for example).
- That local proxy exposes primitives that can be used to manage things like retry logic, encryption mechanisms, custom routing rules, service discovery, and more. A collection of those proxies form a “mesh” of services that now share common network traffic management properties.
- Those proxies can be controlled from a centralized control plane where operators can compose a policy that affects the behavior of the entire mesh.
Different Service Mesh Plane
Data Plane
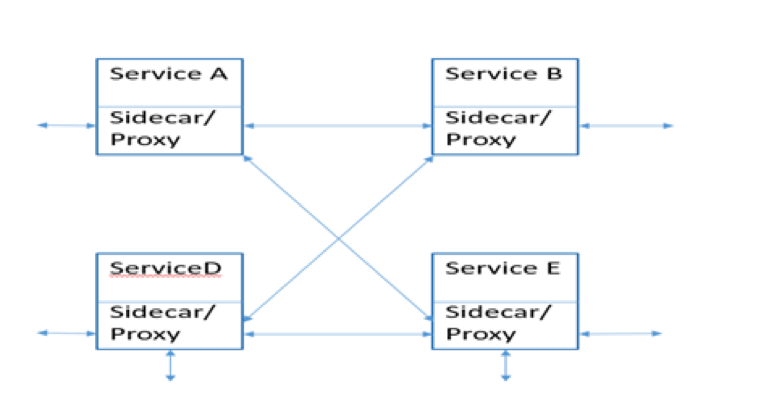
- It can be configured as a Sidecar or Front Proxy. Sidecar is like an extension to the services. Whatever goes in/out from the service will be through Sidecar. The proxy runs alongside the main service as it is injected into each pod.
- Touches every packet/request in the system. Responsible for service discovery, health checking, routing, load balancing, authentication/authorization, and observability.
- Said another way, The data plane is responsible for conditionally translating, forwarding, and observing every network packet that flows to and from a service instance.
- Examples are Linkerd, NGINX, HAProxy, Envoy, Traefik, etc.
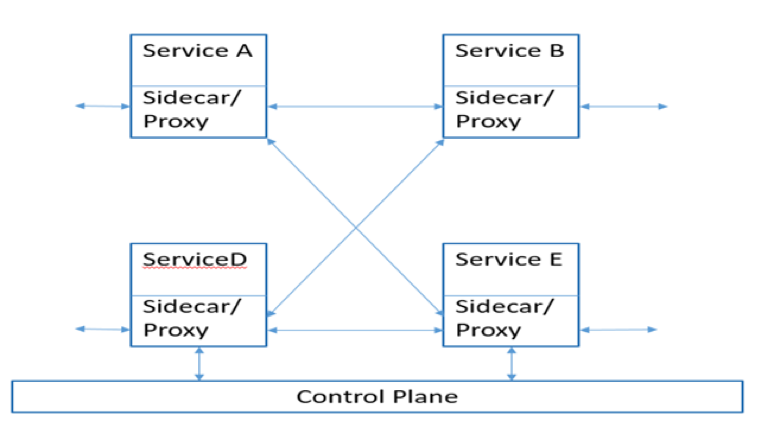
Control Plane
- Provides policy and configuration for all of the running data planes in the mesh. Does not touch any packets/requests in the system. The control plane turns all of the data planes into a distributed system.
- Ultimately, the goal of a control plane is to set policy that will eventually be enacted by the data plane
- Examples: Istio, Nelson, SmartStack.
We will cover Data Plane and Control Plane in detail in the next blog post. Till then stay tuned….